Emulating Emulsion Emulating Emulsion Emulating Emulsion Emulating Emulsion Emulating Emulsion
Emulating Emulsion Emulating Emulsion Emulating Emulsion Emulating Emulsion Emulating Emulsion
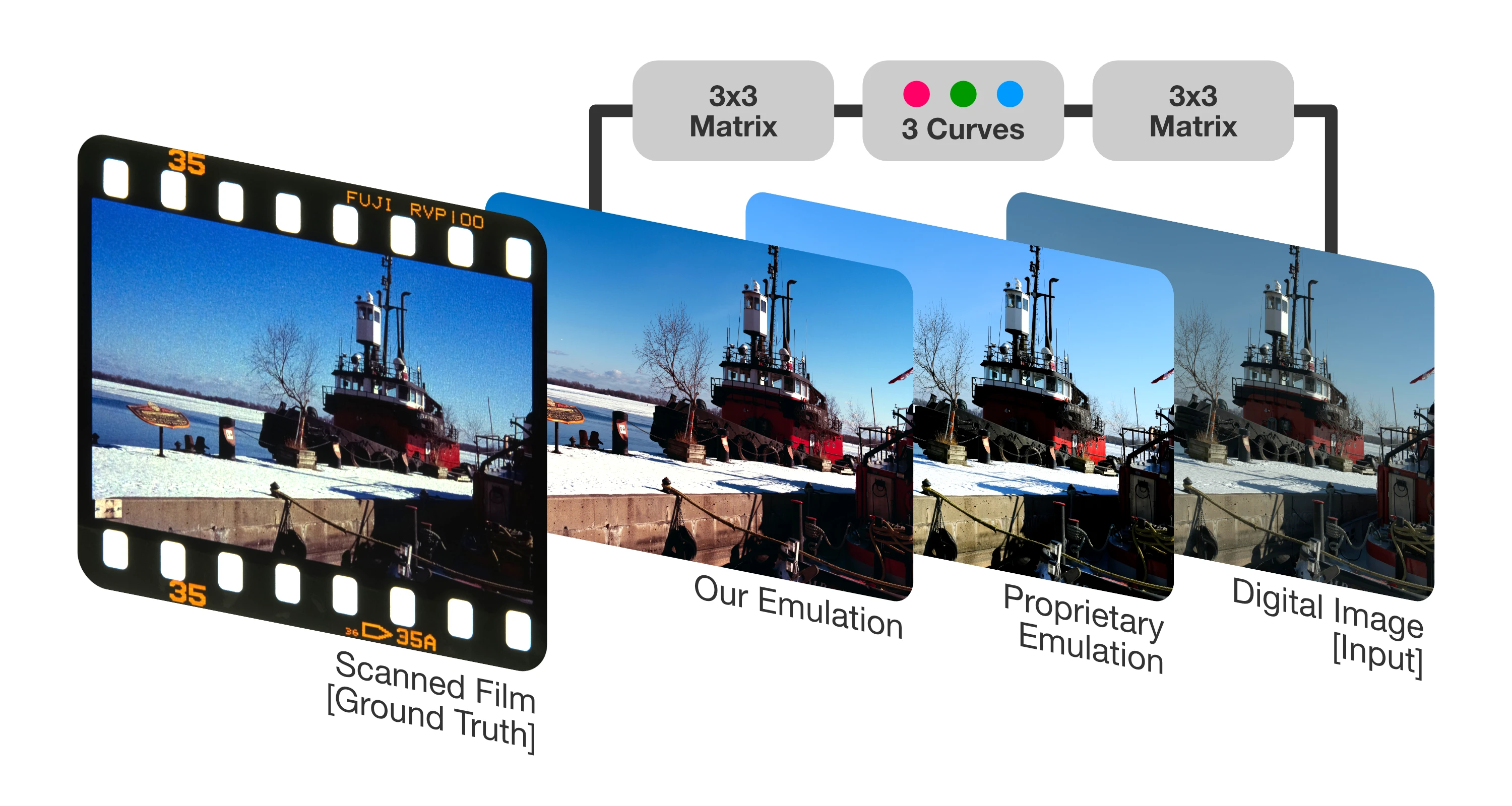 We present a compact, physically-based model that faithfully emulates the colour response of positive photographic film from a digital RAW image.
We present a compact, physically-based model that faithfully emulates the colour response of positive photographic film from a digital RAW image.
Unlike hand-crafted look-up tables (LUT) or data-hungry neural networks, our approach analytically mirrors the film “capture-develop–scan” chain, all with around 30 trainable parameters. Least-squares optimisation is performed on 3168 colour patch pairs captured on one roll of Fujifilm VELVIA 100. Qualitative comparisons show the proposed model more closely matches real film than proprietary methods, and offers artefact-free rendering over discrete LUTs. The continuous model offers production-ready film emulation and a path for archival of discontinued stocks.
Full paper and poster available.
| SIGGRAPH Posters 2025 Abstract | Full Paper |

I am incredibly grateful to Professor Michael Brown and Dr. Hakki Karaimer for their guidance and feedback, as well as Professor Kyros Kutulakos for giving me a chance to begin this project.
Photographic film emulation is widespread among both camera manufacturers and photographers. Even after digital sensors overtook film, decades of research and development devoted to “pleasing” film colour were transplanted into digital picture styles. Today, photographers who never touched film still pursue its look: hundreds of Adobe Lightroom “Film Presets” exist, and Fujifilm’s in‑camera “Film Simulations” remain best‑sellers (Artaius, 2024). Yet most emulation workflows are limited to (1) manual tweaks in an editor, (2) opaque LUT mappings, or (3) proprietary pipelines hidden from the public. To overcome such limitations, we propose a model that is accurate, concise and physically grounded.
Our model targets the core colour and tone‑forming stages of a colour‑positive film workflow so that a digital RAW file can be processed to match a chosen film stock. Design criteria are:
Non‑colour artefacts such as grain, halation and flare are outside our scope, and we focus on colour‑positive film only.
“Radiometric calibration” is the process of estimating a digital camera’s in‑camera pipeline: tone curves, white balance (WB), colour‑space transforms (CST) and gamut mapping, so that RAW images can be reconstructed from, or mapped to, processed images. Classic methods (Lin et al., 2011; Kim et al., 2012) model the chain with two $3 \times 3$ matrices for WB and CST, a nonlinear gamut‑mapping term implemented via radial‑basis functions (RBF) and three per‑channel tone curves. These models accurately reproduced proprietary styles and recovered RAW data for several commercial digital cameras. Similarly, our goal is to transform a digital RAW into the RAW that a scan of a specific colour‑positive film would yield. But simply transplanting a digital camera model to film is inadequate. Film introduces an analogue capture stage, chemical development and a separate scanning step; radiometric calibration pipelines omit this extra capture, as detailed in Section Consequence of Scanning.
Early work (Bakke et al., 2009) paired colour chart images shot with both digital and film cameras, then fitted a polynomial from the digital RGBs to the scanned‑film RGBs. Recent efforts employ neural networks: FilmNet (Li et al., 2023) trains a multi‑scale U‑Net on 5000 synthetically generated digital-“film” pairs, while (Mackeenzie et al., 2024) uses an end‑to‑end convolutional neural network (CNN) on generic image pairs. Photographic community projects include LUT construction from known colour patches (David, 2013) and small multilayer perceptrons (MLPs) trained on synthetic Fujifilm “Film Simulation” RAW-JPEG pairs (Anonymous, 2024). Across these approaches, a black‑box function is fitted directly between digital input and scanned‑film or synthetically emulated film output. Such models are neither physically grounded nor interpretable, and it is difficult to confirm whether they model the target film accurately. Moreover, most rely on synthetic film images (i.e. the training images are also emulations); only (Bakke et al, 2009; Mackeenzie et al., 2024) use real scans, and even they treat the scanning pipeline as part of the black box.
Style‑transfer research offers more general solutions. A differentiable network in (Tseng et al., 2022) learns slider parameters compatible with Adobe Camera RAW, while (Hu et al., 2018) can infer a style from exemplar images alone, eliminating the need for paired data sets. These frameworks are powerful but overly general for film: by constraining the domain to colour-positive film colour, we can craft a much simpler model and a lightweight data collection routine.
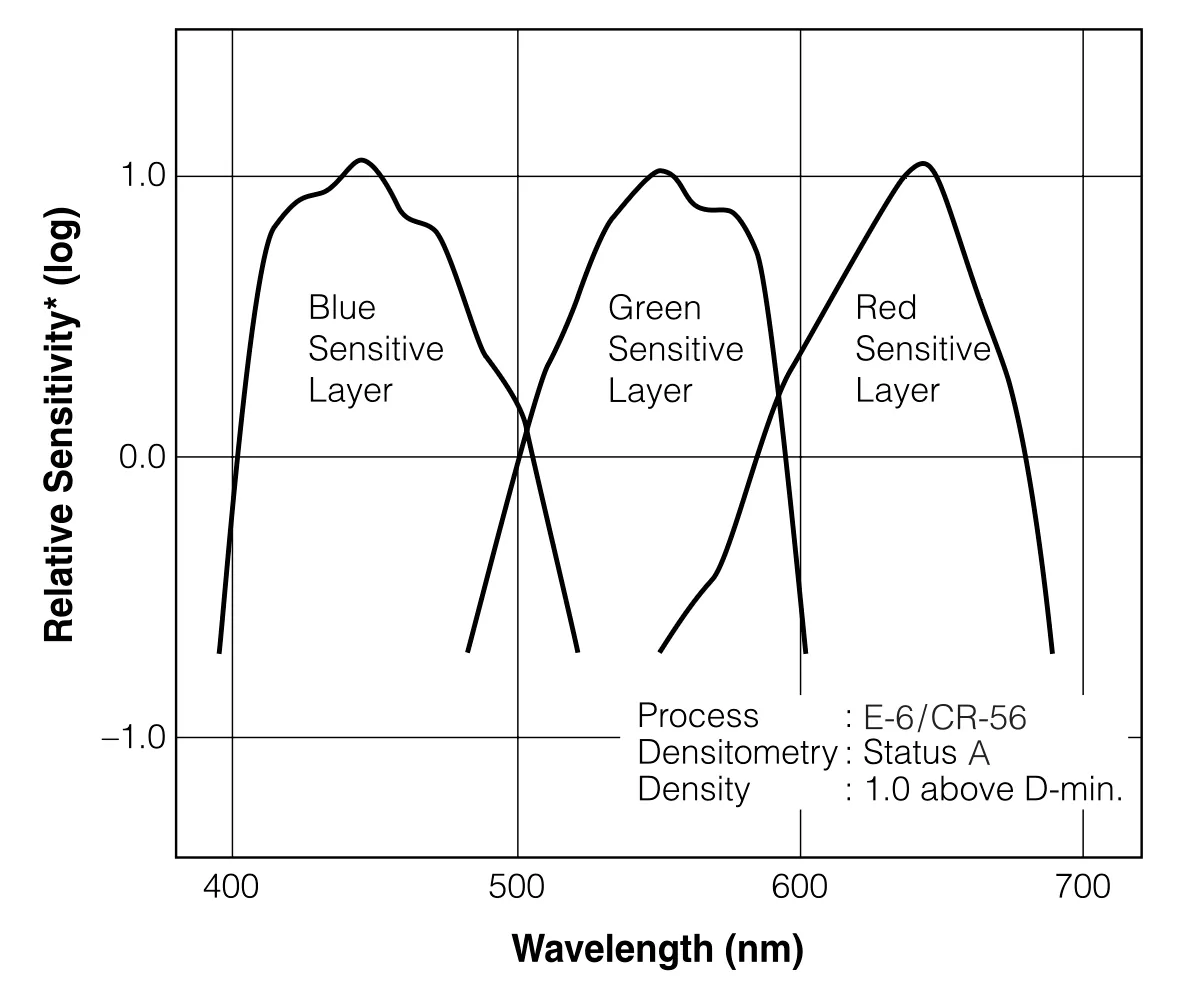
Colour film comprises three dye‑coupled silver‑halide layers, each with its own spectral sensitivity to incoming light (exposure). That is, each layer will “collect” light from a specific range of wavelengths. Such spectral sensitivities contributes to a film’s “look”, analogous to a digital sensor’s colour‑filter array (CFA) and its sensitivities.
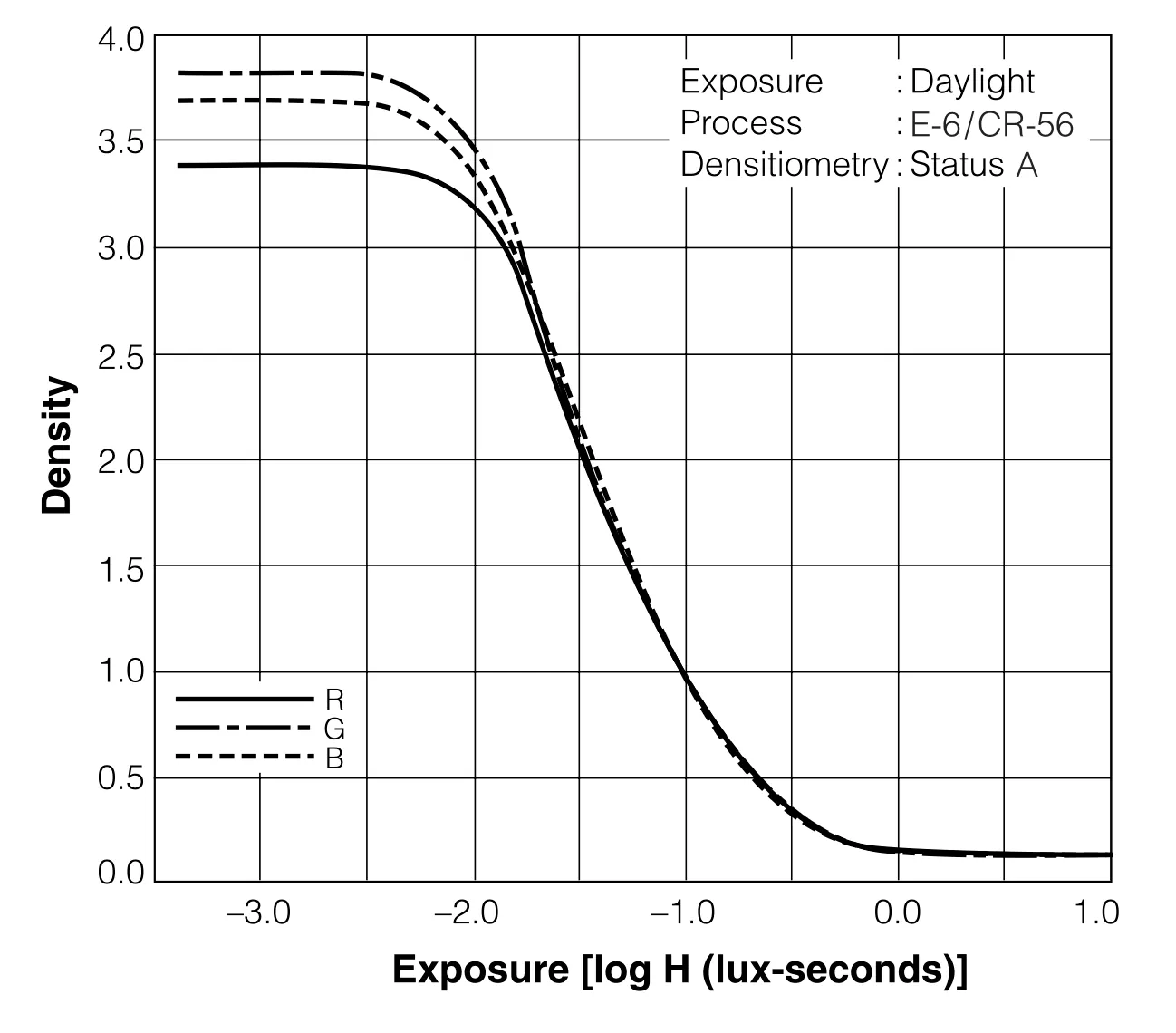
Once a film layer is sensitised by incoming light (exposure), they result in a certain response, also known as optical density. In layman’s terms, the amount of exposure determines whether a layer becomes dark (opaque) or transparent. For film, exposure response follows an S‑shaped curve, also called the characteristic curve. Whether a curve is increasing or decreasing is determined by the film’s type:

Unlike film, modern digital sensors have a mostly linear response to exposure. For example, if the exposure was 1 (arbitrary unit) and the resulting value recorded was 100, an exposure of 2 would result in a value of 200. This is not true for film.
Historically, film was either printed on paper (colour-negative) or viewed over a backlight (colour-positive). Nowadays, many capture the developed frame with a digital camera or scanner, introducing a second digital capture stage after the original capture. In our emulation we will specifically deal with colour-positive film on top of a backlight, which is then captured with a digital camera.


For the remainder of this work, we adopt the following symbols (device $x \in {\mathrm{digital}, \mathrm{film}, \mathrm{scan}}$):
These definitions lay the groundwork for the model in the next section.
Our proposed workflow is as follows:
Therefore, our objective is to transform a digital‑camera RAW $R_\mathrm{digital}$ into an emulated scanned film RAW $R_\mathrm{scan}’$ so that $R_\mathrm{scan}’ \approx R_\mathrm{scan}$. This is a RAW‑to‑RAW mapping, avoiding gamut‑clipping complications and keeps the model early in the pipeline. Section Working in a Device‑Independent Space discusses alternative wide‑gamut spaces.
In the context of the overview diagram from before, we aim to map between the two images highlighted in red:
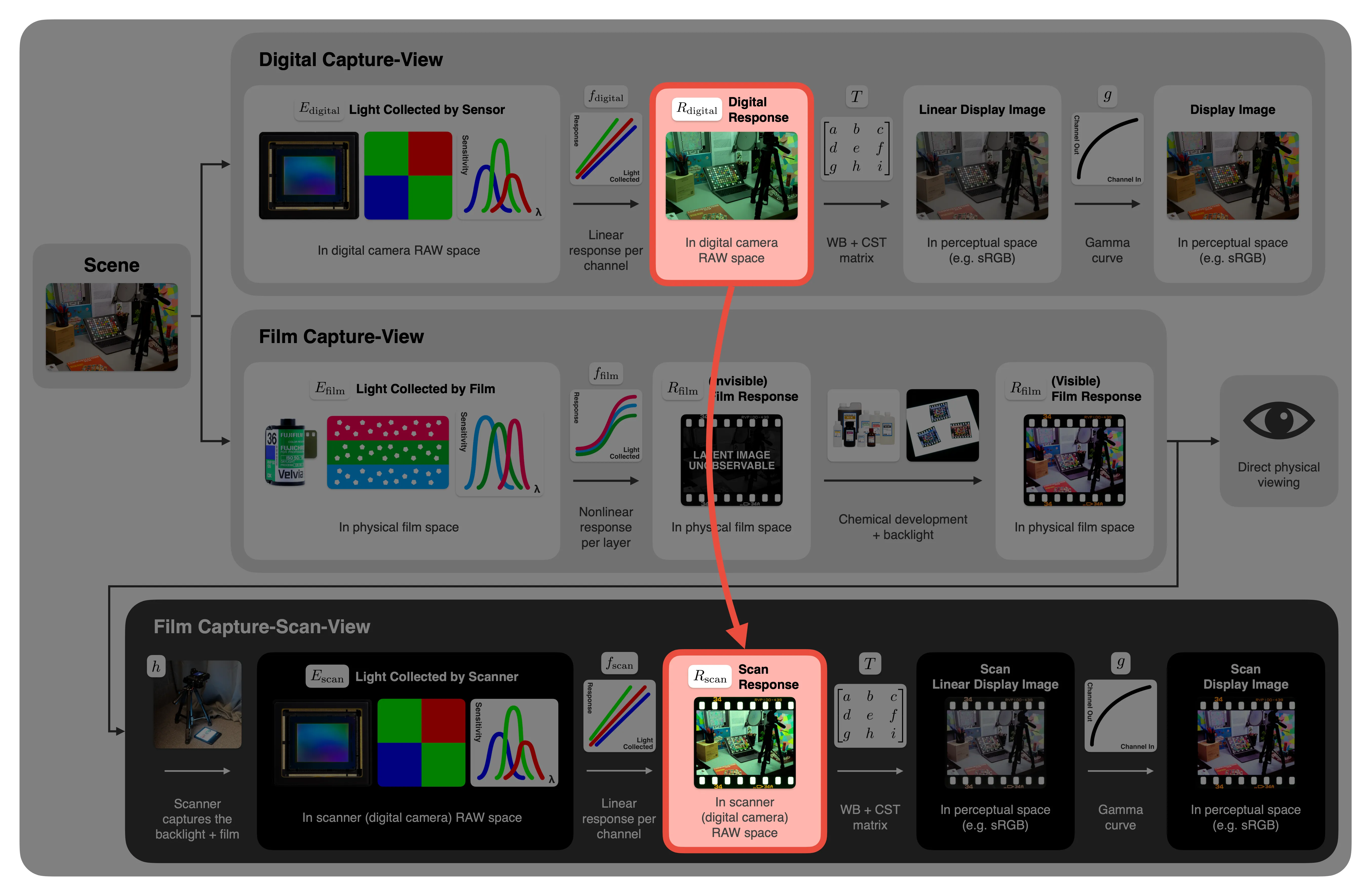
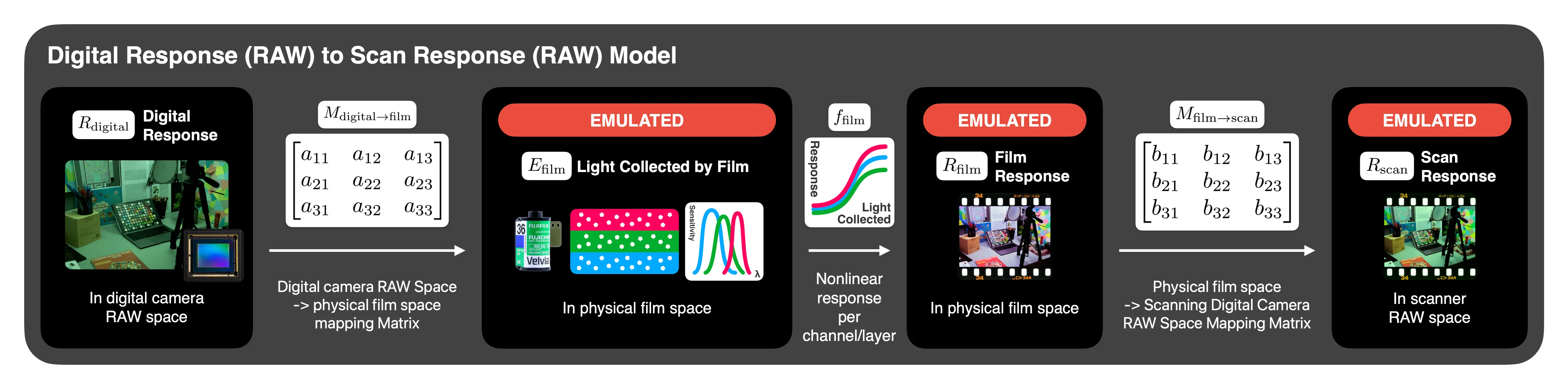
The model mirrors the physical “capture-develop-scan” process in three steps. Given a digital RAW image input $R_\mathrm{digital}$:
Emulate the film response: Each film layer exhibits an S‑shaped characteristic curve $f_{\mathrm{film}, \mathrm{channel}}’$. Following Kodak guidelines (Eastman Kodak Company, 1999), we use a per‑channel sigmoid in log exposure:
\[R_{\mathrm{film},\mathrm{channel}}’ = f_{\mathrm{film}, \mathrm{channel}}’(E_{\mathrm{film},\mathrm{channel}}') = \frac{A}{1 + e^{-k(E_{\mathrm{film},\mathrm{channel}}' - x_0)}} + y_0,\]with four parameters $(A,k,x_0,y_0)$ per $\mathrm{channel}\in{r,g,b}$.
Emulate the scan: At this stage, we are still representing values in terms of the film’s emulated per-layer response (optical density) and we need to map them into the emulated scanner’s RAW values. Because backlights are simple, fixed-brightness illuminants, we may assume that $E_\mathrm{scan}’$, the light collected by the scanner’s sensor, is simply linear to the film optical densities $R_\mathrm{film}’$. As established, $R_\mathrm{scan}’$ is simply linear in $E_\mathrm{scan}’$ as well. Combined, we have another $3 \times 3$ matrix $M_{\mathrm{film} \rightarrow\mathrm{digital}}$ such that:
The complete transformation is therefore:
\[R_\mathrm{scan}’ = M_{\mathrm{film} \rightarrow\mathrm{scan}}\,f_\mathrm{film}'\!\bigl(M_{\mathrm{digital} \rightarrow \mathrm{film}}\,R_\mathrm{digital}\bigr),\]with 30 parameters (9 + 12 + 9) and 36 if including bias terms for the two matrices.
Digital‑camera pipelines use WB + CST -> nonlinear tone curves -> (optionally) nonlinear gamut mapping. Our film model replaces the arbitrary nonlinear tone curves with physically motivated sigmoids and adds the second matrix $M_{\mathrm{film} \rightarrow\mathrm{scan}}$ after the characteristic curves stage to account for the extra scanning step absent in digital‑only workflows.
When the same digital camera both photographs the scene and scans the developed film, the two spectral‑sensitivity sets coincide. In that case, $M_2$ can be replaced by $M_1^{-1}$, dropping 9 (12 if including bias) parameters with negligible loss of accuracy (see Section Experimental Results).
We jointly fit all parameters with nonlinear least‑squares on a dataset of 3168 colour‑patch correspondences captured on a single 36‑exposure roll of Fujifilm VELVIA 100. From there, SciPy’s least-squares optimiser converges reliably from zero‑initialised parameters.
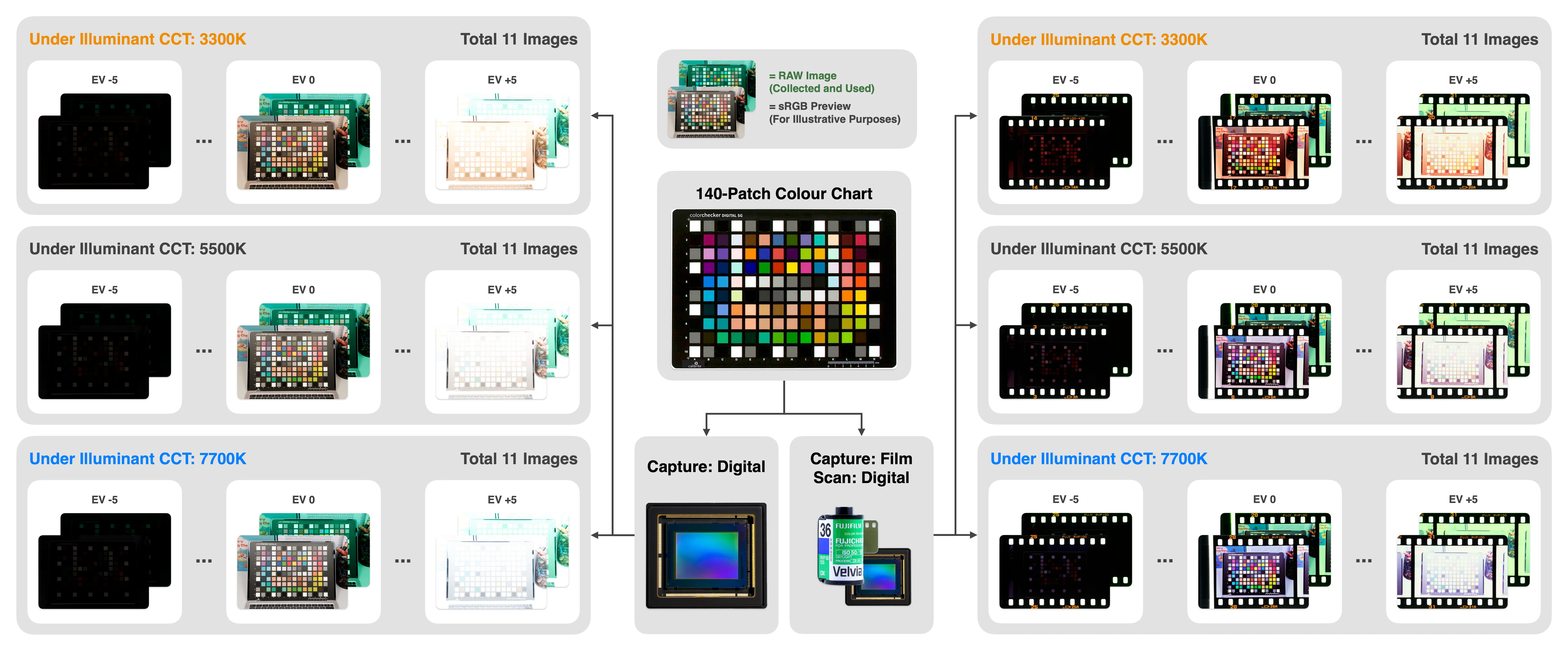
We trained and evaluated our model on Fujifilm VELVIA 100, a colour‑positive film renowned for its high saturation and characteristic reddish bias (Rockwell, 2007). VELVIA’s pronounced palette makes evaluation more reliable than subtler stocks. Both the digital scene‑capture and scanning devices were Fujifilm X‑PRO3 cameras. The film scene-capture device was NIKON F2AS. To generate many correspondences from a single 36‑exposure roll, we photographed the 140‑patch X-Rite Digital SG ColourChart under three distinct illuminants: correlated colour temperature (CCT) 3300K, 5500K and 7700K, and at 11 exposure levels in 1 exposure value (EV) steps. Exposure parameters (shutter speed, aperture, ISO) were synchronised between the two scene-capture cameras. The resulting data set comprises $3 \times 11 = 33$ image pairs and $33 \times 140 = 4620$ patch pairs. Excluding the replicated border patches leaves 3168 unique correspondences, sufficient to fit all 30 model parameters. For film scanning, we used a D50 backlight at $1000 \mathrm{cd/m^2}$. For each image we:
This workflow avoids pixel‑wise alignment and mitigates colour noise, motion blur and minor focus errors, keeping data capture simple enough for enthusiasts while yielding many correspondences.
Our goal is an emulation such that, when a digital camera and a film camera capture the same scene under identical settings, the digital image processed through our model is perceptually similar to the scanned film. We therefore report both:
Baselines are:
| Model | Five‑fold average RMSE across 140 patches |
|---|---|
| LUT (Baseline 1) | 0.0111 |
| Matrix + Curves (Baseline 2) | 0.0149 |
| Proposed Model ($M_{\mathrm{digital} \rightarrow \mathrm{film}}$ + Curves + $M_{\mathrm{film} \rightarrow\mathrm{digital}}$) | 0.0116 |
| Proposed Model (Alt.) ($M_{\mathrm{digital} \rightarrow \mathrm{film}}$ + Curves + $M_{\mathrm{digital} \rightarrow \mathrm{film}}^{-1}$) | 0.0120 |
We notice that the LUT baseline, our propose model, and our alternative proposed model both perform similarly when tested on the 140-patch colour chart. The Matrix + Curves baseline performs slightly worse.
However, RMSE alone does not paint the whole picture. Below are two example scenes, one outdoors and one indoors, rendered across the best-performing models from the quantitative results:

One might think: “If the only issue with a basic LUT constructed from captured point pairs is interpolation error, can’t you just capture more points and/or with better uniformity?”, to which we introduce one of our model’s unique advantages…
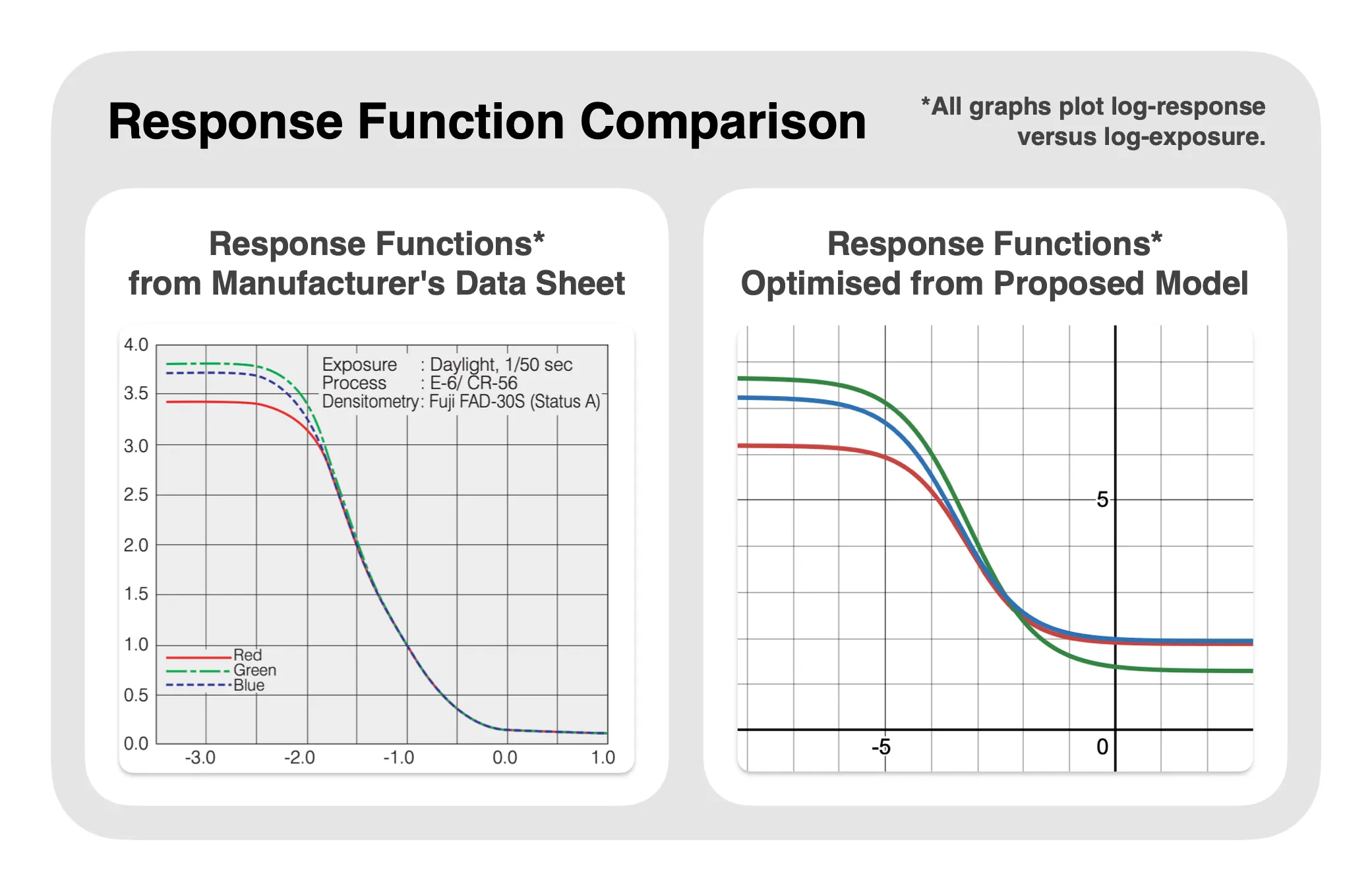
Notice that our model’s 12 curve (sigmoid) parameters ($A,k,x_0,y_0$ per channel) correspond directly to film characteristic curves. The above figure plots the optimised curves alongside the manufacturer data sheet for Fujifilm VELVIA 100. The ordering and shape of the red, green and blue curves align closely, validating the physical plausibility of the fitted parameters. Note that axis units may differ between physical density and RAW space. Unlike with black-box models, such interpretability may allow for some interesting use cases, such as physically-based tuning of the characteristic curves, or the derivation of curve parameters straight from the data sheet.
The proposed model learns a mapping from digital‑camera RAW space $R_\mathrm{digital}$ to scanned-film RAW space $R_\mathrm{scan}$, both of which are sensor‑dependent. Consequently, inference requires the same sensor used during training. A simple remedy is to operate in a sensor‑independent colour space: e.g. CIE XYZ or ProPhoto RGB, before parameter optimisation. For every image pair in the data set we may apply the camera‑specific WB + CST (Fixed. No spatially dependent AWB, for example) matrices once to obtain sensor-independent values, then fit the model in that space. This is feasible because the matrices are fixed across the dataset and during inference, and film itself is deterministic as well as spatially independent. In practice, optimisation and evaluation in ProPhoto RGB produced metrics indistinguishable from RAW‑space, and the provided source code will also operate in ProPhoto RGB space.
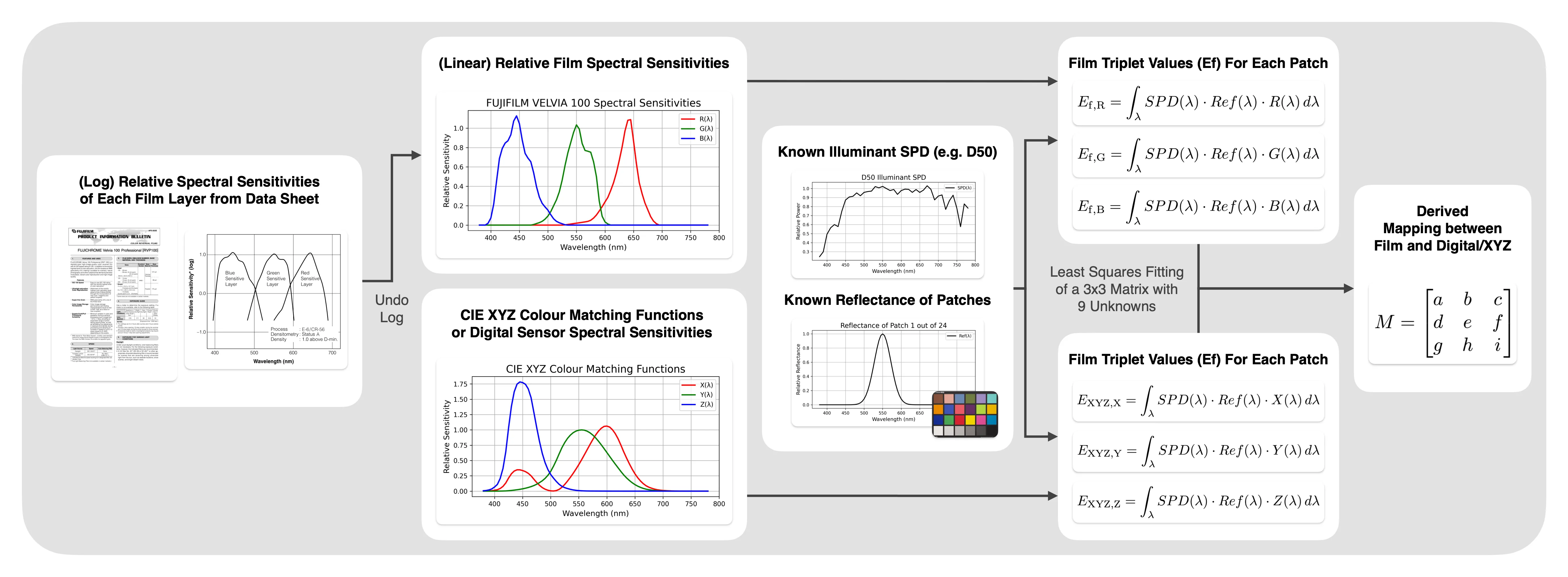
By design, both mapping matrices and the 12 characteristic curve parameters are grounded in some physical transformation. We also verify the latter through comparison with the manufacturer’s data sheet. Therefore, we hypothesise that all parameters may be completely derived from the data sheet alone, as the exact spectral sensitivities and characteristic curves are provided. This may allow the revival of long-lost discontinued film such as the famous Kodak KODACHROME without even capturing any data. While deriving the characteristic curve is straightforward (manual inspection, least squares, etc.), it cannot be said the same for the two matrices. Below is a hypothetical methodology for deriving either matrix based on the spectral sensitivities of film and a digital sensor (or colour-matching functions of XYZ), although yet to be experimented with.
We introduced a compact, physically grounded model for emulating colour‑positive film from digital images. By analysing the dual‑capture nature of scanned film and encoding it with two linear matrices and per‑channel sigmoids, we achieved accuracy on a par with and arbitrary interpolator LUTs while retaining interpretability and requiring only 1 film roll’s worth of captured image pairs for training. Experiments confirmed the necessity of the second matrix that models scanning and demonstrated visual fidelity on real‑world scenes.
James Artaius. Here’s why fujifilm x100vi preorders are off the charts – and it’s a lesson for other camera companies. https://www.techradar.com/cameras/compact-cameras/heres-why-fujifilm-x100vi-preorders-are-off-the-charts-and-its-a-lesson-for-other-camera-companies, 2024. Accessed: 2025-04-16.
Haiting Lin, Seon Joo Kim, Sabine Süsstrunk, and Michael S. Brown. Revisiting radiometric calibration for color computer vision. In 2011 International Conference on Computer Vision, pages 129–136, 2011.
Seon Joo Kim, Hai Ting Lin, Zheng Lu, Sabine Süsstrunk, Stephen Lin, and Michael S. Brown. A new in-camera imaging model for color computer vision and its application. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(12):2289–2302, 2012.
Arne M. Bakke, Jon Y. Harderberg, and Steffen Paul. Simulation of film media in motion picture production using a digital still camera. Image Quality and System Performance VI, vol. 7242, International Society for Optics and Photonics, SPIE, 2009.
Zinuo Li, Xuhang Chen, Shuqiang Wang, and Chi-Man Pun. A large-scale film style dataset for learning multi-frequency driven film enhancement. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI-23), pages 1689–1696, International Joint Conferences on Artificial Intelligence Organization, 2023.
Pierre Mackeenzie, Mika Sengehaas, and Raphael Achodou. Cnns for style transfer of digital to film photography, 2024.
Pat David. Film emulation presets in g’mic/gimp. https://patdavid.net/2013/08/film-emulation-presets-in-gmic-gimp/, 2013. Accessed: 2025-04-16.
LiftGammaGain forum user. Reverse-engineering fujifilm film simulations using a nn + lut. https://www.liftgammagain.com/forum/index.php?threads/reverse-engineering-fujifilm-film-simulations-using-a-nn-lut.18794/, 2024. Accessed: 2025-04-16.
Dan Tseng, Yuxuan Zhang, Lars Jebe, Xuaner Zhang, Zhihao Xia, Yifei Fan, Felix Heide, and Jiawen Chen. Neural photo-finishing. ACM Trans. Graph., 41(6), 2022.
Yuanming Hu, Hao He, Chenxi Xu, Baoyuan Wang, and Stephen Lin. Exposure: A white-box photo post-processing framework. ACM Trans. Graph., 37(2), 2018.
Eastman Kodak Company. Basic photographic sensitometry workbook, 1999. Available from film data archives and enthusiast resources.
Ken Rockwell. Fujifilm velvia 100. https://www.kenrockwell.com/fuji/velvia100.htm, 2007. Accessed: 2025-04-16.
National Geographic. The end of kodachrome. https://www.nationalgeographic.org/the-end-of-kodachrome/, 2010. Accessed: 2025-04-16.